Abbildung 4.4: Instruction Fetch Unit
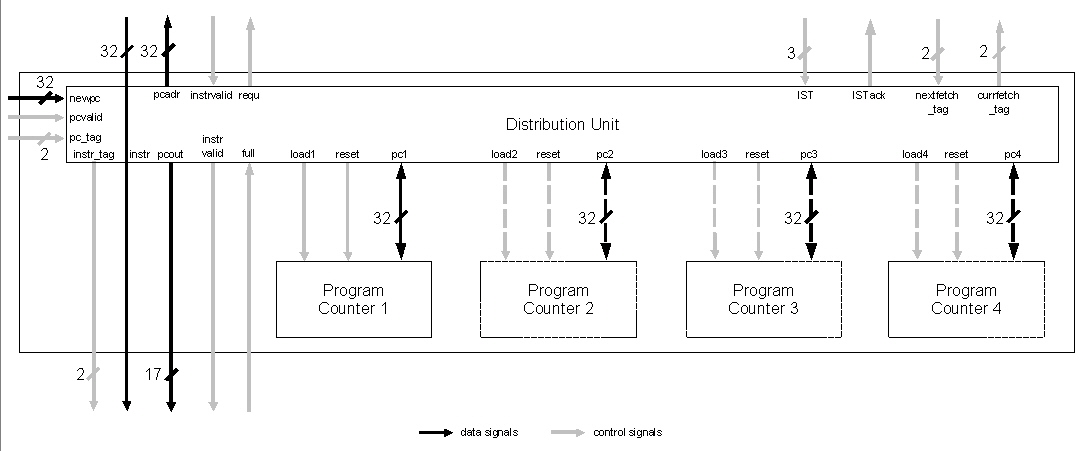
Wird in der Dekodierstufe ein Sprungbefehl erkannt, so muß die dazugehörige Zieladresse (Sprungadresse) in der Ausführungsstufe berechnet werden (aus den Operanden). Diese wird dann an die Befehlsholestufe mit einer Kennung (tag) für den zugehörigen Thread weitergegeben, so daß dessen PC überschrieben werden kann. Da bei Nicht-Vorhandensein der richtigen nächsten Anweisung im Puffer nach einem Sprung dieser Befehlspuffer komplett gelöscht werden muß, existieren verschiedene Strategien für den Umgang mit diesem Problem.
Die erste Variante des Pipeline-Prototypen beinhaltet den einfachsten Fall, daß bei Auftreten eines Sprungs vorerst ganz normal weitergearbeitet wird. Dies entspricht der Strategie "always not taken". Diese und andere Vorgehensweisen werden auch in [16] vorgestellt.
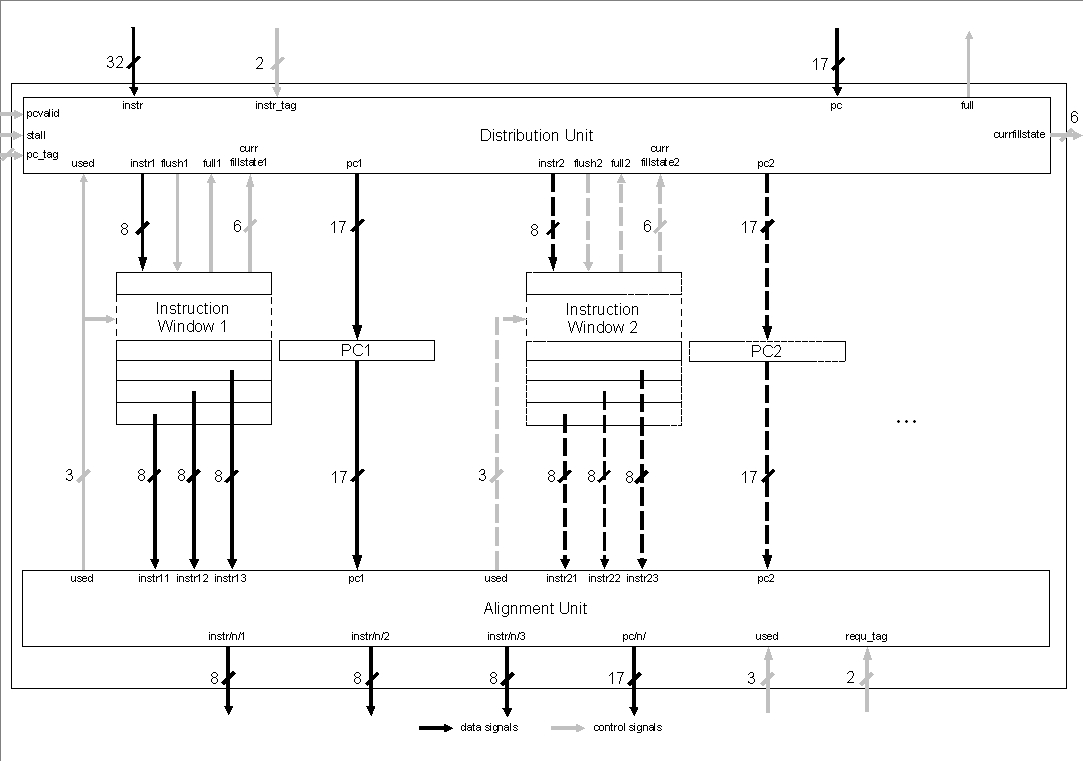
Der nachfolgende Befehlspuffer ist für die Speicherung der Instruktionen in einem Puffer zuständig, auf den die Dekodierstufe zugreift. Dieser Pufferspeicher stellt somit die Pufferregister zwischen der ersten und der zweiten Pipelinestufe dar, leistet aber mehr als das:
Pro Kontrollfaden existieren im Instruction Window zwei Speicherstrukturen: das Schieberegister für den Befehlspuffer und der Befehlszählerpuffer. Der Befehlspuffer erhält eine Länge von acht Einträgen bei einer Wortbreite von 8 Bit, also einem Byte. Diese Zahlen ergeben sich aus folgender Überlegung: Der kürzeste Befehl im Bytecode (dieser wird im Befehlspuffer zwischengespeichert) hat eine Länge von einem Byte, der längste fünf Byte. Untersuchungen der Firma Sun Microsystems Inc. ([9], [13]) haben gezeigt, daß die mittlere Länge eines Bytecode-Befehls 1,8 Byte beträgt. Dann faßt der Puffer maximal acht, minimal eine und durchschnittlich vier Instruktionen. Simulationsergebnisse mit Zahlenbeispielen zu Puffergröße und Fetch-Strategie sind in [26] dokumentiert.
Problematisch wird bei dieser Art der Befehlsverwaltung die Übermittlung des Befehlszählers an die nachfolgenden Stufen: Der Speicherzugriff erfolgt mit einer Datenwortbreite von 32 Bit, während die weitere Verarbeitung mit einer Wortbreite von 8 Bit vor sich geht. Es müssen also unterschiedliche Zählerstände von der Befehlsholestufe an die Schnittstelleneinheit und an den Befehlspuffer weitergegeben werden.
Eigentlich müssen dafür zwei verschiedene Zähler vorgesehen werden. Eine Neuzuweisung des PC zu den einzelnen bytelangen Instruktionsblöcken, die hintereinander in den Befehlspuffer geschrieben werden, wäre sowieso nötig, weil sonst nur zu jedem vierten Befehl ein Zählerstand verfügbar wäre (die 32 Bit müssen auf 8Bit umgebrochen werden). Dies würde bedeuten, daß pro Befehlsspeicherstelle eine Befehlszählerspeicherstelle vorgesehen werden müßte.
In Abb. 4.5 a) steht ein Kasten für eine Speicherstelle des Puffers. Diese kann im Falle des Befehlspuffers links durch eine Instruktion n belegt (I1..n) oder nicht belegt sein (N). Der Befehlszählerpuffer rechts enthält den zur Instruktion n gehörigen Programmzählerstand n (PC1..n) oder ist nicht belegt. Da jedoch immer vier Einträge für den Befehlspuffer mit einem PC am Eingang anliegen, sind die dazwischenliegenden Einträge zunächst unbekannt (??).
Man kann den einen Zähler jedoch einsparen (b)), indem der aktuelle Zählerstand in der Befehlspuffereinheit aus dem momentan gültigen Zählerstand für die Schnittstelleneinheit ständig neu berechnet wird. Vom Aufwand her dürften die beiden Möglichkeiten der Implementierung ungefähr gleich sein, zumal bei Variante b) die Anzahl der Befehlszählerpuffer auf 1 verringert werden kann.
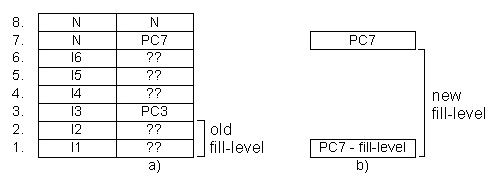
Die Berechnung des neuen Befehlszeigerwertes am Ausgang des Befehlspuffers wird weiter vereinfacht, wenn der PC in der Befehlsholestufe nicht um 1 hochgezählt wird (wie für einen Zugriff auf die nächste Speicherstelle zu erwarten wäre), sondern um 4. Dabei werden die beiden niederwertigsten Bits (0 und 1) nur für die Weitergabe an den Befehlspuffer verwendet, die Adresse für die Speicheransteuerung geben die höherwertigen Bits an (beim Prototypen 2 bis 18). Abb. 4.6 zeigt den grundsätzlichen Aufbau der Instruction Window Unit.