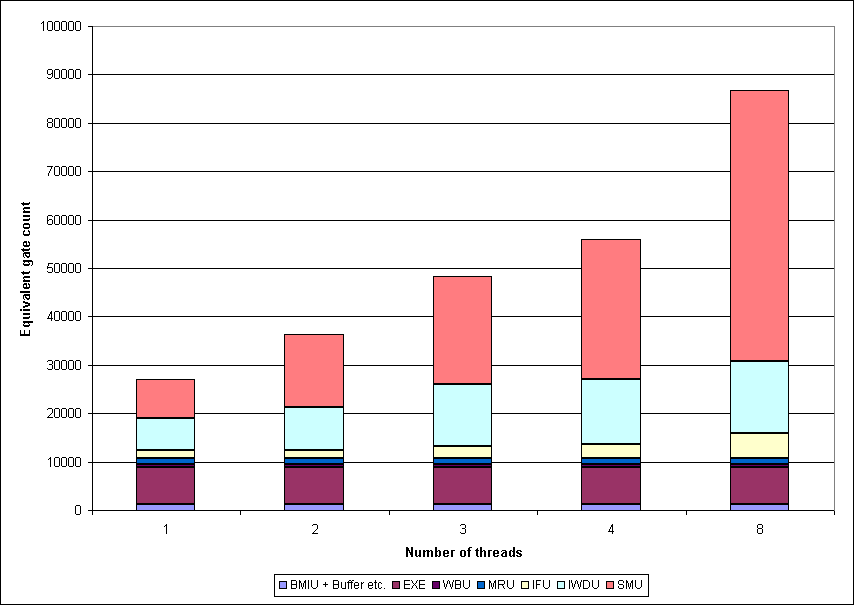
Figure 6.1: Equivalent gate count per block and thread
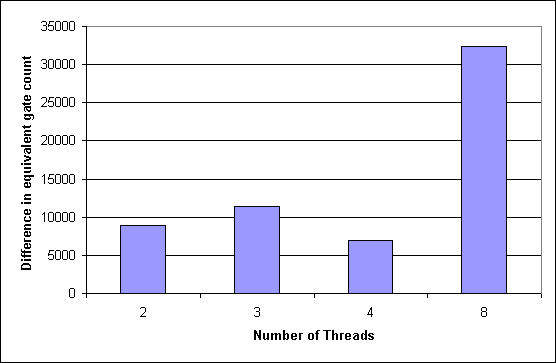
Figure 6.2: Differences in equivalent gate counts per thread
Trying an implementation of a multithreaded pipeline results in a ressource problem: The single-threaded variant which can execute the instructions mentioned in section 4.4.3 without imul and idiv needs the whole XC 4036 XL chip. With an equivalent gate count of about 27200 it needs all of the 1296 configurable logic blocks (CLB) of the FPGA. So there is no capacity left although some more "unrelated logic" might be put into already used blocks. But then the routing problem will become worse.
The FPGA's CLB distribute to the functional blocks of the prototype like seen in table 6.2). All of those numbers differ a bit from synthesis to synthesis, and one configurable logic block can be used several times as long as functionality is not spoiled. This can be a explanation for value 0 in column #CLB of row MRU.
|
Table 6.2 contains two rows for the execution unit: EXE shows the results of an execution unit with instructions named in section 4.4.3 without imul and idiv, but with the added instructions read_global0, read_global1, write_pc, write_optop, write_global0 und write_global1. EXEx contains all instruction of EXE plus imul.
An evaluation for the size of an FPGA to implement a multithreaded pipeline can be given on base of the differences in size of the blocks per thread:
27200 gates are used for the single-threaded pipeline without multiplication and division. The stack memory consists of 32 memory cells that are 32 Bit wide with one write port and two read ports. Two microcodes are implemented in the Microcode-ROM Unit.
A very simple implementation of multithreaded functional blocks without any optimizations is used for the fetch stage, the instruction window & decode unit and for stack memory to evaluate average changes in ressource needs per thread. The results are shown in table 6.3. Costs for additional coding bits (thread tag) have been taken into account.
|
While mapping the multithreaded pipelines into the FPGA the computer states that the chosen device is too small for those circuits. But it also states the ressource needs shown in table 6.4. With respect to the structure of the execution stage a differentiation into pipeline without multiplication (Mapping) and with multiplication (Mappingx) is done. In comparison to the single-threaded variant ressource needs for synthesis have changed: about 150 MB of RAM are needed. No runtime measurement can be done because of the device problem mentioned above.
|
The numbers for the eight-threaded microcontroller must be seen as a prognosis out of the averages per thread and coding tag bits.
The results are shown in figure 6.1 for a pipeline without multiplication. The equivalent gate count seems to rise almost linearly with the number of threads, but with an additional offset for every new coding bit of the thread tag. Therefore the difference to the one smaller number of threads is greater with three threads than with four. The next offset must be added when creating numbers for five threads, the following with nine. Taking this as a criterion, for best used ressources the number of threads should be a power of two.
To implement the single-threaded pipeline designed here in an FPGA without multiplication the XC 4036 XL is big enough. When moving to a four-threaded pipeline an XC 4085 XL with a maximum equivalent gate count of 85000 should be taken. Then the rest of 20000 equivalent gate counts might be used for hardware scheduling by the priority management unit and the signal unit.
When turning this design into a full microcontroller with e. g. an analog/digital-changer, RS232-, CAN-bus- and other interfaces, the additional ressource needs of these functional blocks have to be considered.
With respect to those arguments the decision could fall for a device out of Xilinx' Virtex family, that can replace 200000 gates at maximum (XCV200). The properties of embedded systems may lead to the low power variant XCV200E. Another point may be that a number of memory cells are used in the Komodo-Mikrocontroller. The extended memory type of virtex low power devices then seems to be interesting for further implementations. These are proposals based on technical reference (Xilinx, [31], a complete cost analysis cannot be done here.